人以类聚,物以群分。在当今大数据的时代,利用机器学习的方法对大样本、大数据进行量化、根据每个数据的特征值进行分类,打标签;从而挖掘数据的价值,例如商家根据用户群体的分类,和标签定向的推送广告。对数据的聚类有多种方式,其中最经典的就是,基于数据密度和基于数据层次进行聚类。
基于密度聚类
Density Base spatial clustering of application with noise
定义:
密度聚类算法:假设通过样本数据之间分布的紧密程度,能够反应数据的聚类结构;这是算法的假定前提。算法的具体实现通常基于样本之间的可连接性,将可以连接的样本聚在一类,并不断扩大聚类簇,获得最终的聚类结果
1.ε-:定义一个样本的邻近区域:该区域包含在数据集D中与给定样本点Xj的距离小于ε-的样本点;
2.核心对象: 样本点Xj邻域范围内包含的样本点数目,大于等于阀值MinPts
3.密度直达:X1位于X2的邻域范围内,同时X2为核心对象(跟很多人有关系),则X1则由X2密度直达
4.密度可达:两个样本点通过一系列密度直达样本对(Xi,Xi+1)建立联系
5.密度相连:两个样本同时和某一个样本点密度可达
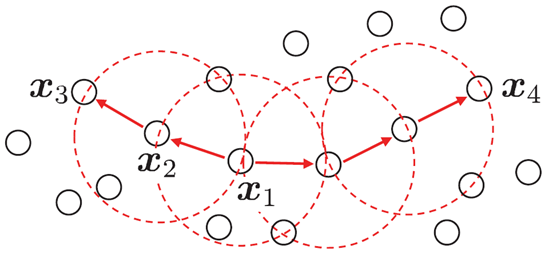
优化目标
密度聚类中,同一簇中密度相连数满足最大,密度可达满足最大;不难推出当同一类样本中密度可达达到最大时,就满足优化目标
算法流程
1.假定邻域距离ε- 与Minpts样本数目
2.计算样本中核心对象数据集Ω
3.随机获取核心数据集中的一个核心对象最为种子
4.根据递归迭代思想,对数据集进行迭代,当第一个随机核心对象组成的簇满足优化目标时,将第一簇数据从数据集中剔除,进入下一次迭代
5.直至所有核心对象被迭代完毕,聚类就结束
特点
1.MinPat设置的是整个数据集的邻域的最小样本数,但是并不是每一类中的密度都大于等于MinPat。
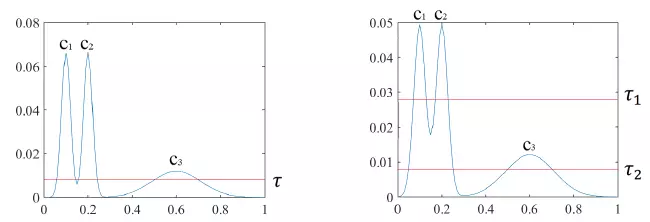
当阀值提高后C3样本点会被当成噪音处理
2.当一个数据点在两个核心数据对象之间时,算法默认将数据点归类到先迭代的核心对象;因此算法不稳定
3.根据密度聚类的思想聚类时,有一些点与所有的核心对象都不相连时,会被算法默认为噪音
基于层次聚类
定义:
层次聚类:在不同层次之间对数据集进行划分;形成类似树形的聚类结果,在划分时可以采用“自底向上”与“自顶向下”进行聚类。
1.自底向上:先将每个样本看成一类,接着对所有进行聚类
2.自顶向下:所有样本看成一类,依次对数据集进行拆分聚类
AGNES算法
不同类之间的距离度量:
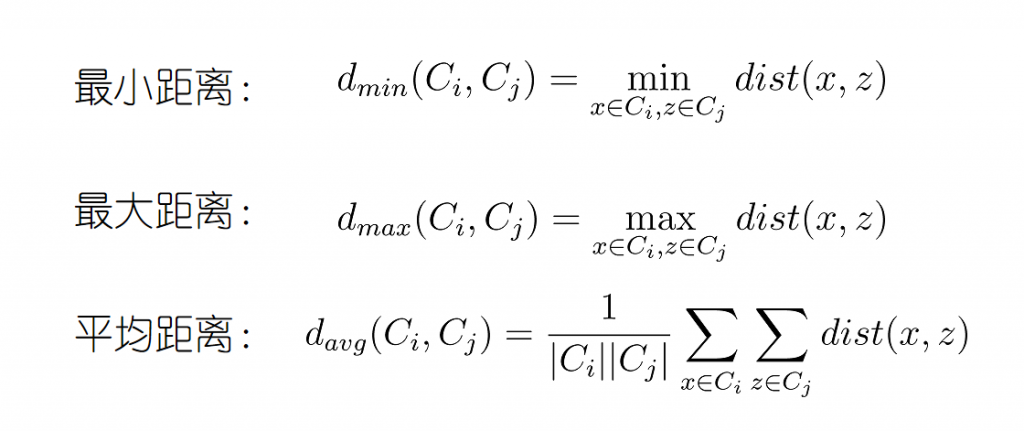
其中最小距离由两个簇中最近的样本点决定;最大距离则由最远样本点决定;平均距离有所有样本共同决定。也被形象的称为“单链接”、“全链接”、“均链接”。
应用范围:
最小值: 这种方法容易受到极端值的影响。
最大值:容易受到极端值的影响.
均值:这种方法计算量比较大,但结果比前两种方法更合理。
算法流程:
1.计算所有样本点两两之间的距离矩阵
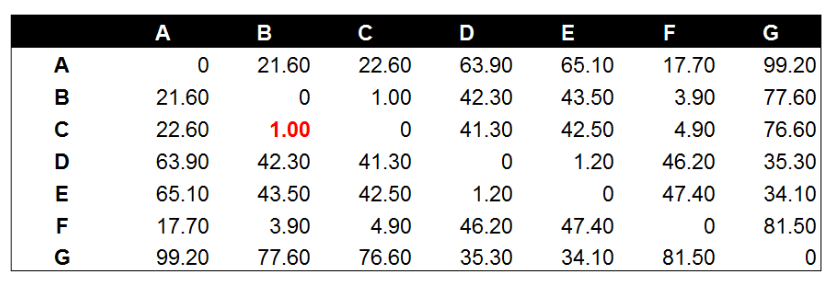
特点:
1.主要应用在数据量比较小的时候
2.算法稳定性比较好
3.选择不同的距离衡量,往往有不同的结果
参考:
机器学习[周志华版]

